我的 AI 编程工作流
这是什么
这是我日常使用的一套 AI 编程工作流。
起点放在任务进来那一刻:先判断任务规模,决定流程要多厚;再扫描高风险触发器,判断能不能直接动手;最后用验证和自查收尾。
整套流程建在两件事上:
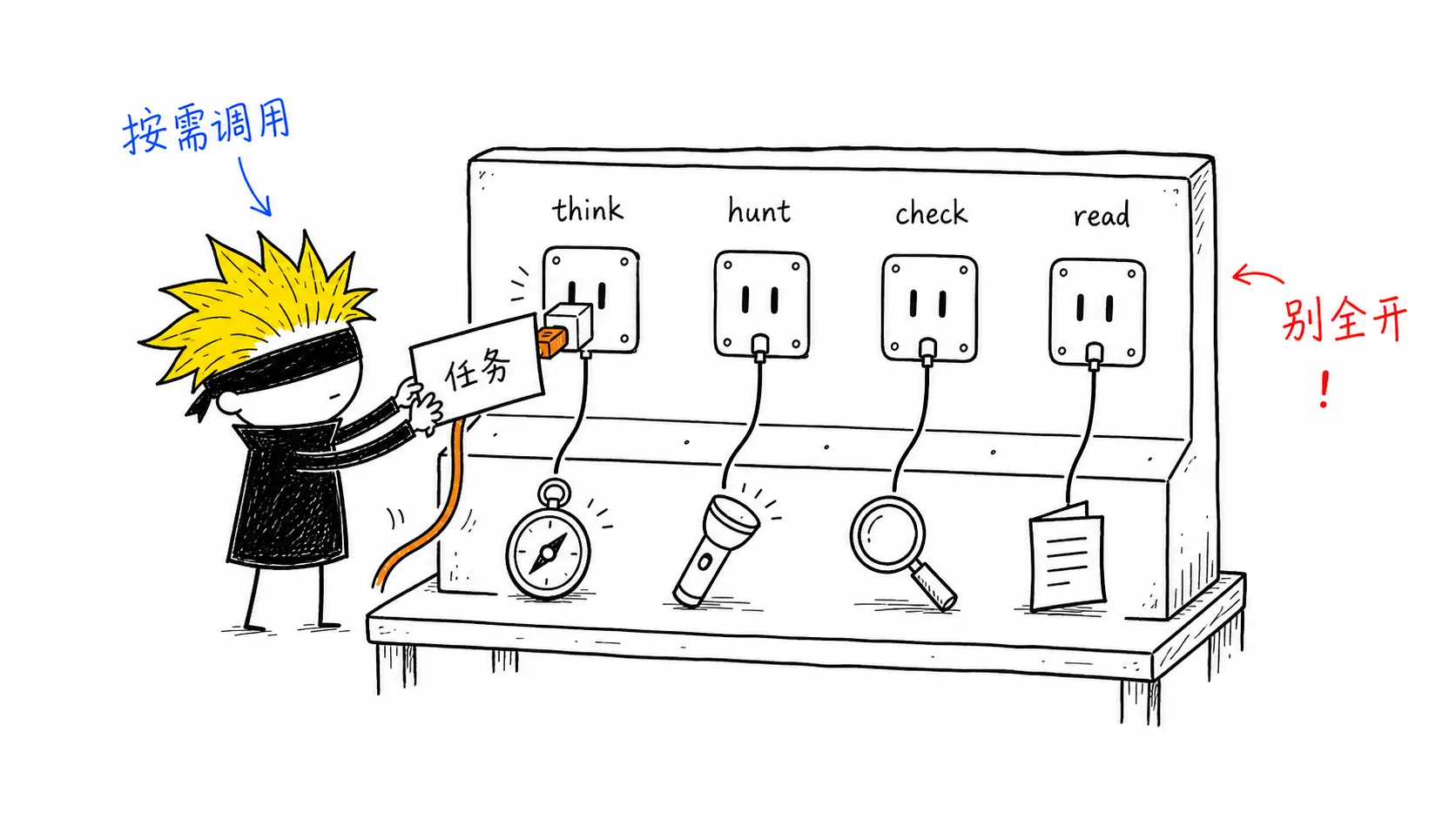
- Waza:把工程习惯固化成 skill 的一组工具(仓库)。我常用 think / hunt / check / read 四个。在 Claude Code 里可以直接调用;换成别的 agent,就把这四个动作当成提示词里的思维步骤。
- 高风险门禁:一条执行规则。只要改动碰到数据、权限、生产、删除、发布,就先确认,再动手。
下文的「agent」指我使用的编程 agent,包括 Claude Code、Codex 或其他类似工具,不绑定具体产品。
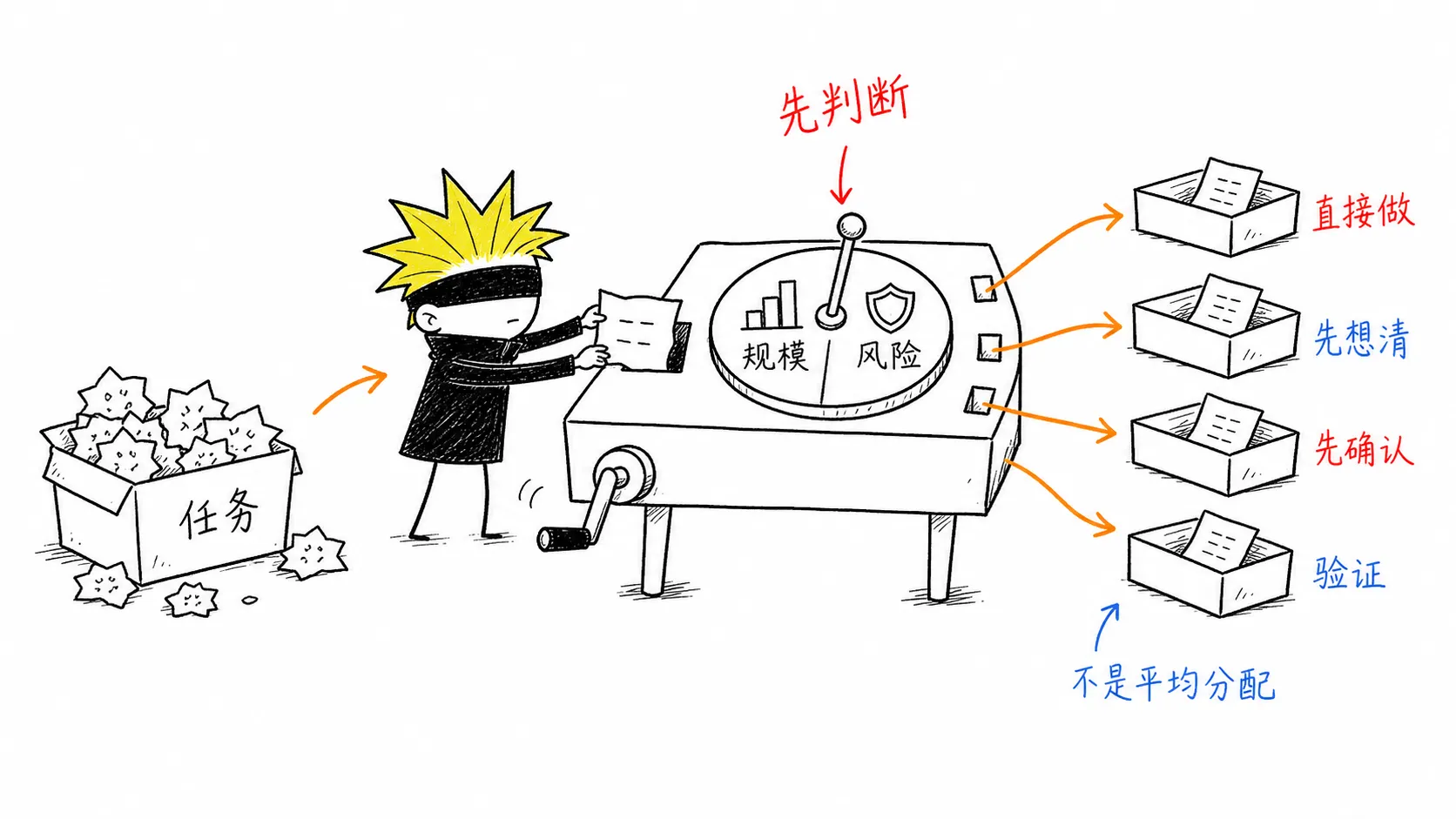
快速上手
只想直接用,按三步走。
1. 装好 skill
按 Waza 仓库 的说明安装,确认 think / hunt / check / read 可用。
2. 每个工程任务开头,把这段发给 agent
先判断任务规模:小、中、大。
再扫描是否触发高风险门禁(数据、权限、生产配置、密钥、删除、Git 历史、发布)。
我可能判断不准,你负责判断并说明理由。
小任务且没触发门禁:直接做,改完跑相关验证,用 check 自查。
中型或大型任务:先用 think 把目标、范围、验收、风险讲清再实现;值得追溯的,收尾把「为什么这么做」写进 commit 或 docs。
触发高风险门禁:先给 6 点确认(解决什么问题 / 用户看到什么 / 不做什么 / 改哪些模块 / 怎么验收 / 最大风险和回滚),我确认前不要改文件。
动手前先读项目规则和 git status,别覆盖我未提交的改动。
动手后必须跑相关验证,不能验证就说清未验证和原因。3. 记住一条硬规则
碰到高风险先确认。其他情况,让 agent 按上面这段自己分流、执行、验证。
到这里已经能跑起来。后面解释为什么要这样设计。
核心思路
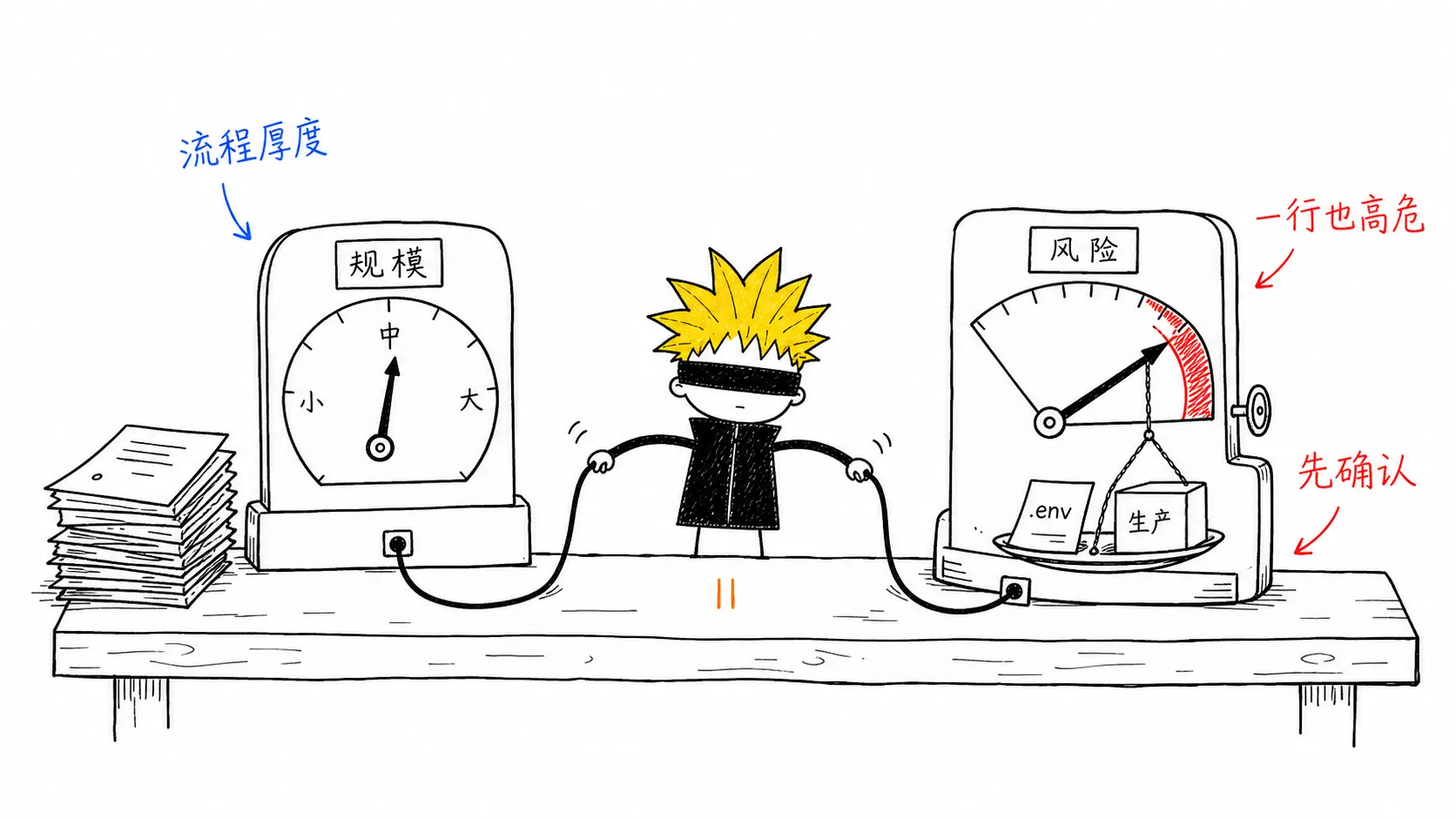
这套流程只判断两件事:规模和风险。
- 规模决定流程厚度。小任务直接做,中大型任务先用 think 定目标、范围、验收和风险。它回答的是:这件事做起来有多复杂?
- 风险决定能否直接动手。命中高风险触发器,就先确认边界和回滚,再改文件。它回答的是:这件事做错的代价有多高?
这两个维度要分开看。一行改动也可能高风险,比如改 .env、删数据、动 CI/CD;一次大文档整理可能工作量不小,但风险很低。
对应到工具上,Waza 负责「怎么想」,门禁负责「能不能动」。
完整流程
读项目 → 分流(规模 + 风险)→ 选通道 → 执行 → 验证 → 收尾
触发高风险门禁时:在分流后插入「6 点确认」,确认后再继续我可以先凭直觉给一个规模初判,比如小、中、大。最终定档交给 agent:是否触发门禁、影响范围、验收标准、验证命令、回滚方式,都由 agent 补齐并说明理由。
第一步:读项目
动手前先读上下文,不直接写代码。
项目规则:AGENTS.md、CLAUDE.md、README、package.json 等清单文件
工作区状态:git status --short --branch -uall
已有验证命令:test、lint、type check、build
未提交改动:标出来,不能覆盖如果当前目录不是 Git 仓库,也要说明。例如 /Users/kerwin/2026zk 是多项目工作区,不是单个仓库。
第二步:分流(规模 + 风险)
先看任务类型。
- bug / 回归:一眼能定位就直接修;查不清就先用 hunt 找根因,根因清楚后再判断规模。
- 新增 / 改动 / 重构:直接进入规模分流。
- 研究 / 文档 / 学习:通常没有根因要查,按规模走;需要消化外部材料时,用 read 或 learn。
再判断规模。
| 规模 | 标准 | 走哪条 |
|---|---|---|
| 小 | 单文件、小文案、小配置、解释代码、跑命令、简单 bug | 小任务通道 |
| 中 | 新功能入口、改一段流程、多文件但不改架构 | think 通道 |
| 大 | 架构调整、跨模块重构、长期维护面扩大 | think 通道,通常分阶段 |
然后扫描高风险触发器。下面任意一条命中,都不能直接改文件,先给「6 点确认」(具体问题见文末「高风险门禁」)。
- 数据库 schema 变更、数据迁移、历史数据写入
- 登录、权限、账号、支付
- CI/CD、生产配置、密钥、
.env - 删除文件或目录
git rebase、git reset --hard、git clean -fgit push、部署、npm publish、发文章、提 PR 到非个人仓库- 影响线上用户、自动化任务、已有数据,或很难回滚
判断不准时,规模往大一档算;风险只要命中触发器,就按高风险处理。
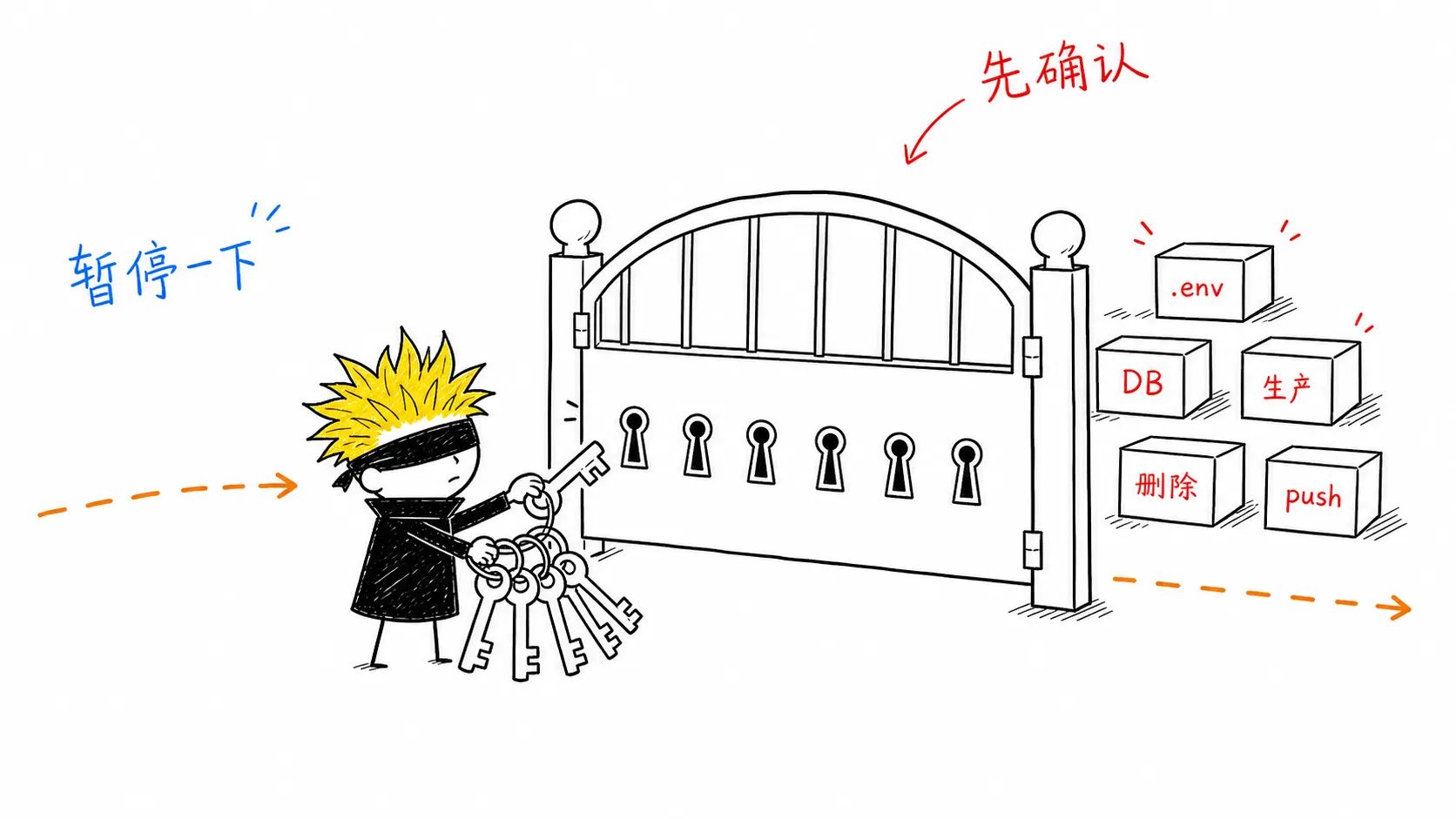
第三步:选执行通道
- 小任务通道:任务小,且没有触发门禁。直接改,跑最相关验证,用 check 自查,再汇报。不必先 think。
- think 通道:中大型任务。先用 think 定目标、范围、验收、风险,再实现;之后跑测试、lint、type check、build,最后用 check 自查。
- 门禁流程:触发高风险时,先过 6 点确认。确认后仍回到原本的通道,只是额外要求分阶段推进、更强验证和更严格 review。
第四步:执行
执行阶段只做当前通道允许的事。
- 不做无关重构,不覆盖未提交改动。
- 不跳过测试,不改测试预期来掩盖 bug。
- 不用
--no-verify、--force绕过校验。 - 同一个错误连续失败时,先找根因,别反复撞命令。
中途发现判断不对,就回退到对应流程。
小任务变复杂 → 升到 think 通道
碰到数据 / 权限 / 生产 → 进高风险门禁
设计不成立 → 回 think 重新定边界第五步:验证
每条通道都要有出口。
最相关测试 → lint → type check → build → 必要时手动冒烟 → checkbugfix 要额外说清三件事:修复前为什么失败、哪条测试证明已经修好、有没有覆盖回归场景。
不能验证时,不要默认通过。写清楚:未验证原因、剩余风险、建议下一步怎么验证。
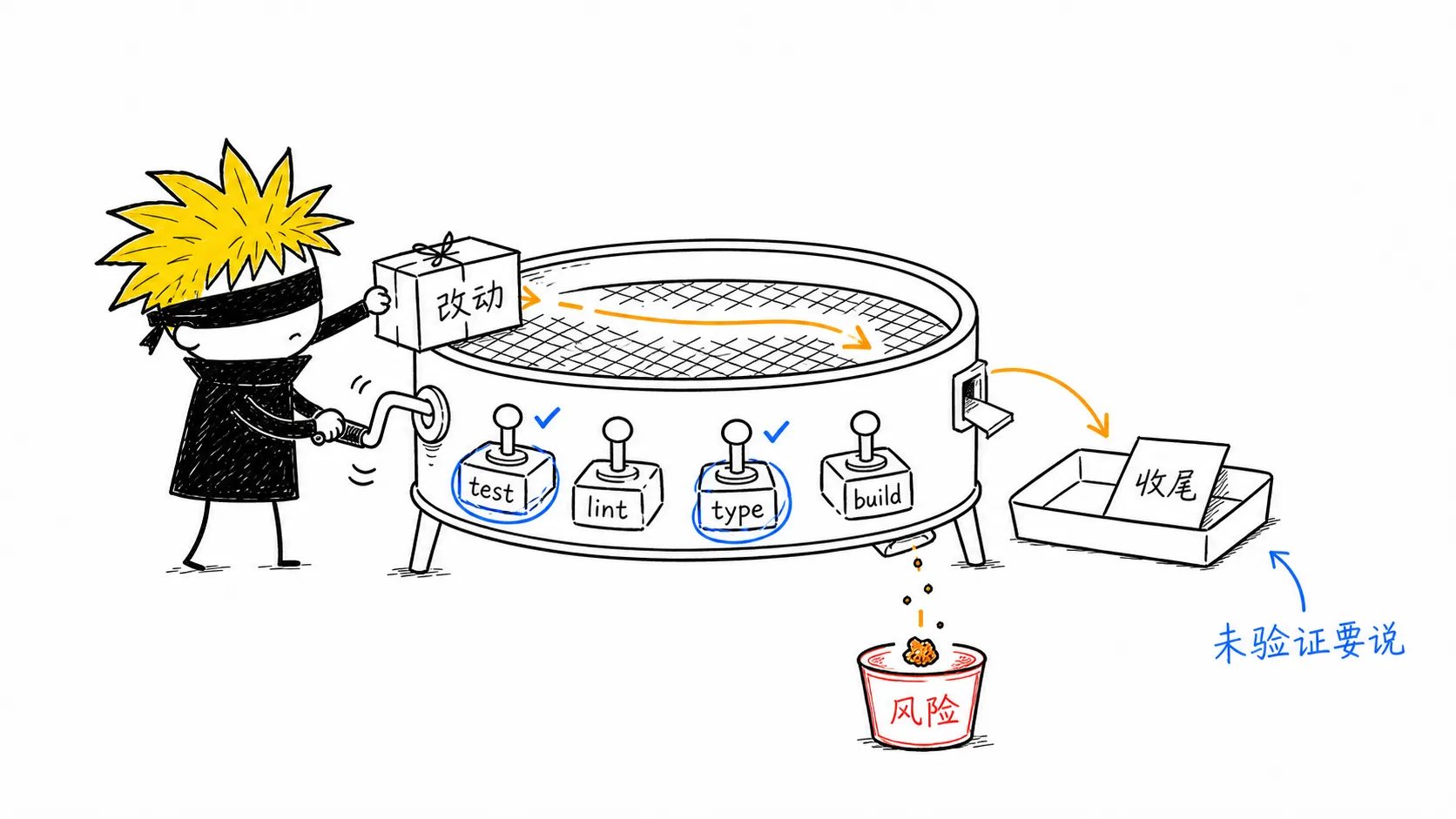
第六步:收尾
收尾只回答四件事:
- 改了什么
- 验证了什么
- 还剩什么风险
- 要不要 commit / push
值得追溯的改动,在这一步留痕:commit body 写清「为什么这么做、放弃了什么方案」,必要时在 docs/ 补一段决策记录,给三个月后的自己看。
小改动不用额外写,git 历史够看。没有明确要求,不 commit、不 push、不发布。
工具与门禁
Waza 四个动作
| 动作 | 什么时候用 | 干什么 |
|---|---|---|
| think | 分流后、实现前 | 判断值不值得做、范围、验收、风险 |
| hunt | bug / 回归时 | 先找根因再修 |
| check | 验证、收尾前 | 查回归、缺测试、风险 |
| read | 读外部链接、PDF、资料 | 提取事实和上下文 |
在单人开发里,check 最关键。平时 agent 像 Writer,负责推进;check 把 Reviewer 视角固定进流程,专门看需求有没有理解错、边界有没有漏、实现是不是过度复杂、测试是否缺失、旧数据旧流程会不会受影响、回滚是否真的可行。
高风险任务才需要更强 Reviewer:换一个模型,或做一次独立 code review。
高风险门禁
门禁是一层叠在原通道上的确认机制,不单独成为第三条执行通道。确认通过后,小任务仍走小任务通道,中大型任务仍走 think 通道,只是多了分阶段、强验证和更严格 review。
命中触发器(清单见第二步)时,先给 6 点确认。
1. 解决什么问题
2. 用户最终看到什么
3. 明确不做什么
4. 改哪些主要模块
5. 怎么验收
6. 最大风险和回滚方式我确认后,agent 再回到对应通道,按确认过的阶段做。commit 只在我明确要求时创建。
一句话
先看规模,决定流程要多厚;再看风险,决定能不能直接改。人的职责是判断值不值得做、给出初始方向;agent 的职责是定档、补齐工程判断,并把影响范围、验收标准、验证命令和回滚方式讲清楚。